Diffbot provides a suite of products built to turn unstructured data from across the web into structured, contextual databases. Diffbot’s products are built off of cutting-edge machine vision and natural language processing software that’s able to parse billions of web pages every day.
Diffbot Knowledge Graph
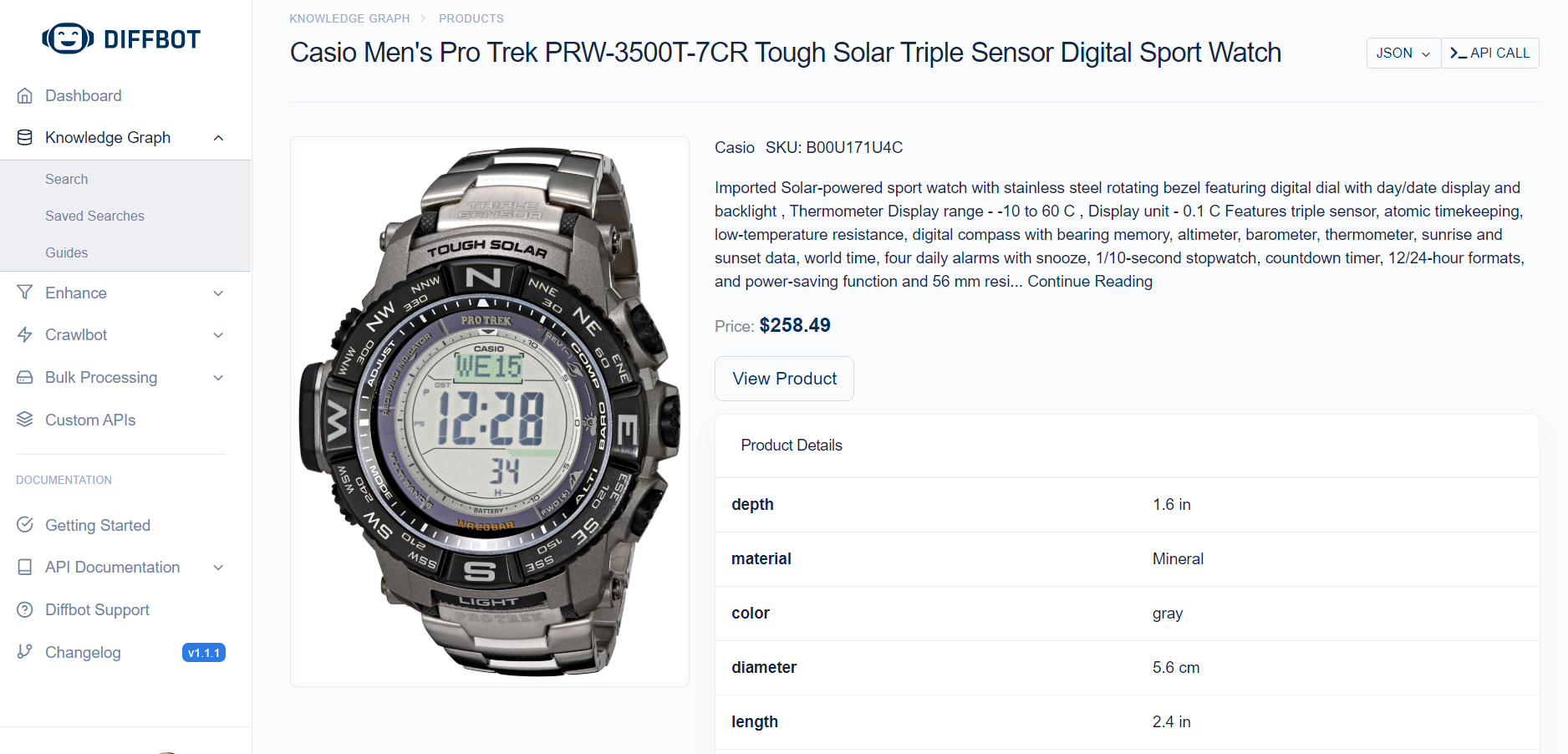
Diffbot’s Knowledge Graph product is the world’s largest contextual database comprised of over 10 billion entities including organizations, people, products, articles, and more. Knowledge Graph’s innovative scraping and fact parsing technologies link up entities into contextual databases, incorporating over 1 trillion “facts” from across the web in nearly live time.
Diffbot Enhance
Diffbot’s Enhance product provides information about organizations and people you already hold some information on. Built off of Knowledge Graph technology, Enhance let’s users build robust data profiles about opportunities they already hold some data on.
Diffbot Data Extraction APIs
Diffbot’s Data Extraction API’s allow you to leverage Diffbot’s innovative web parsing technologies to point them at a predefined list of web properties. Live update information on ecommerce listing, find brand mentions in the news, pull in discussion and review data from across many sites, and more!
Administrator in Computer Software
Advanced user of Diffbot
★★★★★
Diffbot Increases Efficiency
What do you like best?
Prior to using Diffbot, we relied primarily on RSS feeds and a web scraping tool that is based on the visual layout and HTML of a webpage. We were very dependent on X Paths to get the data we wanted. We find that the Diffbot crawlers are more stable in the long term because they are not as impacted by website design changes. This saves us a lot of time that we would otherwise be spending on maintenance.
What do you dislike?
The two issues that are most challenging for us are:
1. Diffbot does not recognize PDF documents, and we frequently would like to ingest them as articles.
2. We find it difficult to troubleshoot a crawler in situations where it is not bringing in data or it is not bringing in the data we are expecting.
What problems are you solving with the product? What benefits have you realized?
The biggest problem that Diffbot solved for us is reducing the amount of maintenance we have to do on our scraped websites. We use heavily Diffbot's full text capability and Diffbot's metadata is also useful for us. The metadata that we use most is Diffbot's language designation to ensure that our clients are seeing only articles in the languages that they choose.
We also see great potential for using the bulk API to become more efficient in our content ingest process and we are excited to continue to explore this option.
Review source: G2.com